Creating an AI-Generated Rock Band
Artificial Intelligence has made a significant impact on many areas, including the world of entertainment. AI-created music and art are gaining popularity, and in this blog, we’ll explore the idea of bringing these two elements together to form an AI-generated rock band.

Abstract
This blog explores the creation of an AI-generated rock band, The Rockbots, utilizing two advanced generative models: Stable-Audio-Open 1.0 for music generation and Stable-Diffusion-XL-Base-1.0 for image creation. Both models run on ZeroGPU Spaces from Hugging Face, offering a seamless and efficient platform for AI-generated content. This study details the methodology, technical frameworks, and outcomes of this innovative project, highlighting the capabilities and limitations of the utilized technologies.
Introduction
The intersection of artificial intelligence and music production has led to groundbreaking advancements in creating original content. The Rockbots, an AI-generated rock band, leverages state-of-the-art AI models to produce music and visual art. This project utilizes Stable-Audio-Open 1.0 for audio generation and Stable-Diffusion-XL-Base-1.0 for image generation, both deployed on ZeroGPU Spaces by Hugging Face. This blog examines the methodologies and technologies employed in this creative endeavor, providing insights into the potential and challenges of AI-generated music and art.
Methodology
Music Generation with Stable-Audio-Open 1.0
Model Description: Stable-Audio-Open 1.0 generates variable-length stereo audio at 44.1kHz from text prompts. The model comprises three components:
- An autoencoder that compresses waveforms into a manageable sequence length.
- A T5-based text embedding for text conditioning.
- A transformer-based diffusion model operating in the latent space of the autoencoder.
Usage Example: The model is used with the stable-audio-tools library for inference, allowing users to generate high-quality audio based on text prompts.
import torch
import torchaudio
from einops import rearrange
from stable_audio_tools import get_pretrained_model
from stable_audio_tools.inference.generation import generate_diffusion_cond
device = "cuda" if torch.cuda.is_available() else "cpu"
model, model_config = get_pretrained_model("stabilityai/stable-audio-open-1.0")
sample_rate = model_config["sample_rate"]
sample_size = model_config["sample_size"]
model = model.to(device)
conditioning = [{
"prompt": "128 BPM Rock beat played in a treated studio",
"seconds_start": 0,
"seconds_total": 30
}]
output = generate_diffusion_cond(
model,
steps=100,
cfg_scale=7,
conditioning=conditioning,
sample_size=sample_size,
sigma_min=0.3,
sigma_max=500,
sampler_type="dpmpp-3m-sde",
device=device
)
output = rearrange(output, "b d n -> d (b n)")
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)Model Details:
- Type: Latent diffusion model based on transformer architecture.
- Language: English.
- License: See LICENSE file for commercial use details.
- Training Dataset: Consists of 486,492 audio recordings from Freesound and Free Music Archive (FMA), all licensed under CC0, CC BY, or CC Sampling+.
- Mitigations: Detailed analyses ensure no unauthorized copyrighted music is present in the training data.
Limitations:
- Inability to generate realistic vocals.
- Primarily trained with English descriptions.
- Variability in performance across different music styles and cultures.
Image Generation with Stable-Diffusion-XL-Base-1.0
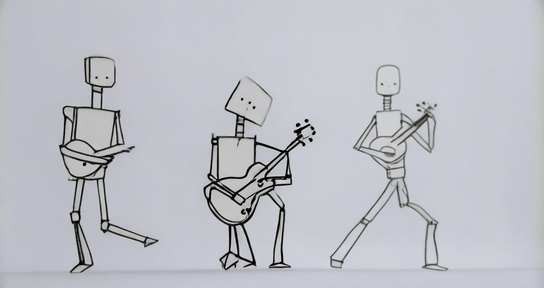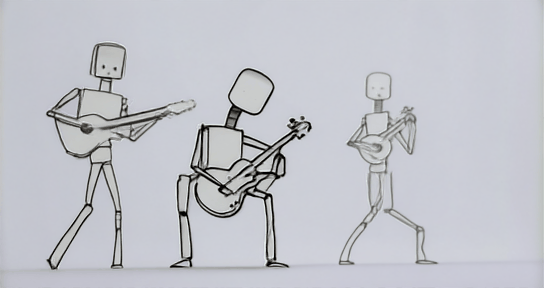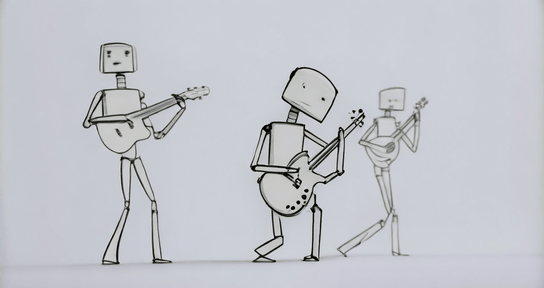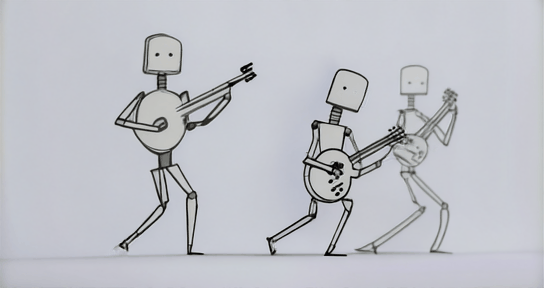
Model Description: Stable-Diffusion-XL-Base-1.0 is a diffusion-based text-to-image generative model developed by Stability AI. It utilizes two fixed, pretrained text encoders and operates through a two-stage latent diffusion process, optionally refined with SDEdit.
Pipeline Usage: The model generates and refines images based on text prompts, employing an ensemble of experts for high-fidelity results.
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
prompt = "One line sketch of robots playing guitars"
images = pipe(prompt=prompt).images[0]Model Details:
- Type: Diffusion-based text-to-image generative model.
- License: CreativeML Open RAIL++-M License.
- Resources: GitHub Repository and SDXL report on arXiv.
Limitations:
- Imperfect photorealism.
- Challenges with rendering complex compositions and legible text.
- Potential social biases inherent in training data.
ZeroGPU Spaces
Description: ZeroGPU Spaces, offered by Hugging Face, provides free GPU access for Spaces and allows them to run on multiple GPUs. Utilizing Nvidia A100 GPU devices, ZeroGPU efficiently allocates GPU resources as needed.
Usage: Functions requiring GPU are decorated with @spaces.GPU, dynamically allocating and releasing GPU resources during function execution.
+import spaces
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(...)
pipe.to('cuda')
+@spaces.GPU
def generate(prompt):
return pipe(prompt).images
gr.Interface(
fn=generate,
inputs=gr.Text(),
outputs=gr.Gallery(),
).launch()Compatibility: ZeroGPU Spaces are compatible with high-level HF libraries like transformers and diffusers, although some compatibility issues may arise with non-Gradio SDK environments.
Results and Discussion
The Rockbots project successfully demonstrates the capabilities of AI in generating high-quality rock music and accompanying visual art. The integration of Stable-Audio-Open 1.0 and Stable-Diffusion-XL-Base-1.0 on ZeroGPU Spaces highlights the potential for seamless, efficient AI content creation.
However, limitations in vocal realism, cultural representation, image compositionality, and the repetitive rhythm of the generated music indicate areas for future improvement. Enhancing vocal synthesis to achieve more natural and expressive performances, incorporating a wider range of cultural influences to enrich diversity, refining image generation algorithms to improve compositional coherence, and introducing more varied and dynamic musical structures could significantly advance the project.
Conclusion
This study showcases the innovative application of AI in music and art creation through The Rockbots project. Utilizing advanced models like Stable-Audio-Open 1.0 and Stable-Diffusion-XL-Base-1.0 on ZeroGPU Spaces, this project pushes the boundaries of AI-generated content.
Additionally, the generated music tracks are being uploaded as NFT music on Audius, a decentralized music-sharing platform. This not only provides a unique way to distribute and monetize AI-generated music but also aligns with the growing trend of using blockchain technology to empower artists and creators. Future work will focus on addressing the identified limitations and exploring new frontiers in AI-driven creativity.
Follow @th3rockbots on Instagram, YouTube, Audius, TikTok and X!
References
- Stability AI. (2024). Models. Retrieved from
https://github.com/Stability-AI - Hugging Face. (2024). ZeroGPU Spaces. Retrieved from https://huggingface.co/spaces/enzostvs/zero-gpu-spaces
